Special Report Lays Out Best Practices for Handling Bias in Radiology AI
Released: August 24, 2022
At A Glance
- With the increasing use of AI in radiology, it is critical to minimize bias within machine learning systems before implementation.
- The researchers suggest mitigation strategies for 12 suboptimal practices that occur within the four data handling steps of machine learning system development.
- Collecting data from multiple institutions from different geographical locations, using data from different vendors, or including public datasets help develop a better training dataset.
- RSNA Media Relations
1-630-590-7762
media@rsna.org - Linda Brooks
1-630-590-7738
lbrooks@rsna.org - Imani Harris
1-630-481-1009
iharris@rsna.org
OAK BROOK, Ill. – With the increasing use of artificial intelligence (AI) in radiology, it is critical to minimize bias within machine learning systems before implementing their use in real-world clinical scenarios, according to a special report published in the journal Radiology: Artificial Intelligence, a journal of the Radiological Society of North America (RSNA).
The report, the first in a three-part series, outlines the suboptimal practices used in the data handling phase of machine learning system development and presents strategies to mitigate them.
"There are 12 suboptimal practices that happen during the data handling phase of developing a machine learning system, each of which can predispose the system to bias," said Bradley J. Erickson, M.D., Ph.D., professor of radiology and director of the AI Lab at the Mayo Clinic, in Rochester, Minnesota. "If these systematic biases are unrecognized or not accurately quantified, suboptimal results will ensue, limiting the application of AI to real-world scenarios."

Dr. Erickson said the topic of proper data handling is gaining more attention, yet guidelines on the correct management of big data are scarce.
"Regulatory challenges and translational gaps still hinder the implementation of machine learning in real-world clinical scenarios. However, we expect the exponential growth in radiology AI systems to accelerate the removal of these barriers," Dr. Erickson said. "To prepare machine learning systems for adoption and clinical implementation, it's critical that we minimize bias."
Within the report, Dr. Erickson and his team suggest mitigation strategies for the 12 suboptimal practices that occur within the four data handling steps of machine learning system development (three for each data handling step), including:
- Data collection—improper identification of the data set, single source of data, unreliable source of data
- Data investigation—inadequate exploratory data analysis, exploratory data analysis with no domain expertise, failing to observe actual data
- Data splitting—leakage between data sets, unrepresentative data sets, overfitting to hyperparameters
- Data engineering—improper feature removal, improper feature rescaling, mismanagement of missing data
Dr. Erickson said medical data is often far from ideally suited as input for machine learning algorithms.
"Each of these steps could be prone to systematic or random biases," he said. "It's the responsibility of developers to accurately handle data in challenging scenarios like data sampling, de-identification, annotation, labeling, and managing missing values."
According to the report, careful planning before data collection should include an in-depth review of clinical and technical literature and collaboration with data science expertise.
"Multidisciplinary machine learning teams should have members or leaders with both data science and domain (clinical) expertise," he said.
To develop a more heterogeneous training dataset, Dr. Erickson and his coauthors suggest collecting data from multiple institutions from different geographical locations, using data from different vendors and from different times, or including public datasets.
"Creating a robust machine learning system requires researchers to do detective work and look for ways in which the data may be fooling you," he said. "Before you put data into the training module, you must analyze it to ensure it's reflective of your target population. AI won't do it for you."
Dr. Erickson said that even after excellent data handling, machine learning systems can still be prone to significant biases. The second and third reports in the Radiology: Artificial Intelligence series focus on biases that occur in the model development and model evaluation and reporting phases.
"In recent years, machine learning has demonstrated its utility in many clinical research areas, from reconstructing images and hypothesis testing to improving diagnostic, prognostic and monitoring tools," Dr. Erickson said. "This series of reports aims to identify erroneous practices during machine learning development and mitigate as many of them as possible."
Editorial links- Hitting the Mark: Reducing Bias in AI Systems https://pubs.rsna.org/doi/10.1148/ryai.220171
- Mitigating Bias in Radiology Machine Learning: 2. Model Development https://pubs.rsna.org/doi/10.1148/ryai.220010
- Mitigating Bias in Radiology Machine Learning: 3. Performance Metrics https://pubs.rsna.org/doi/10.1148/ryai.220061
"Mitigating Bias in Radiology Machine Learning: 1. Data Handling." Collaborating with Dr. Erickson were Pouria Rouzrokh, M.D., M.P.H., M.H.P.E., Bardia Khosravi, M.D., M.P.H., M.H.P.E., Shahriar Faghani, M.D., Mana Moassefi, M.D., Diana V. Vera Garcia, M.D., Yashbir Singh, Ph.D., Kuan Zhang, Ph.D., and Gian Marco Conte, M.D., Ph.D.
Radiology: Artificial Intelligence is edited by Charles E. Kahn Jr., M.D., M.S., Perelman School of Medicine at the University of Pennsylvania, and owned and published by the Radiological Society of North America, Inc. (https://pubs.rsna.org/journal/ai)
RSNA is an association of radiologists, radiation oncologists, medical physicists and related scientists promoting excellence in patient care and health care delivery through education, research and technologic innovation. The Society is based in Oak Brook, Illinois. (RSNA.org)
For patient-friendly information on medical imaging, visit RadiologyInfo.org.
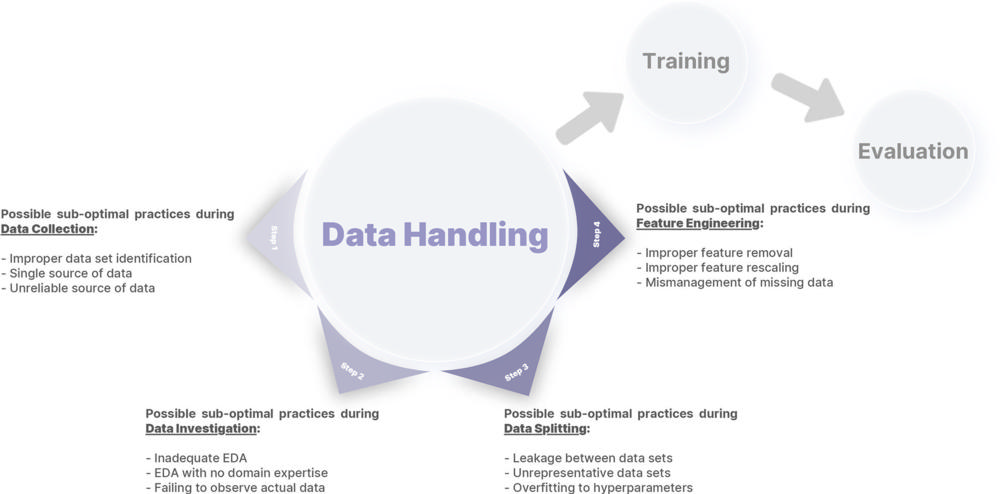
Figure 1. An arbitrary framework for defining data handling, consisting of four different steps: data collection, data investigation, data splitting, and feature engineering. Different errors introduced in this report for each step are also summarized. EDA = exploratory data analysis.
High-res (TIF) version
(Right-click and Save As)

Figure 2. A mosaic photograph of random radiographs was collected from our institutional dataset of patients who underwent total hip arthroplasty. Despite the reduced resolution of individual images, a quick look at this photograph reveals valuable insights for developers who desire training models on this dataset; for example, radiographs have different views, not all radiographs have prostheses, radiographs are from different sexes (the anatomy of pelvis is different between male and female patients), different prosthesis brands are available in the data, some radiographs have outlier intensities (presenting darker or brighter than expected), and so forth.
High-res (TIF) version
(Right-click and Save As)
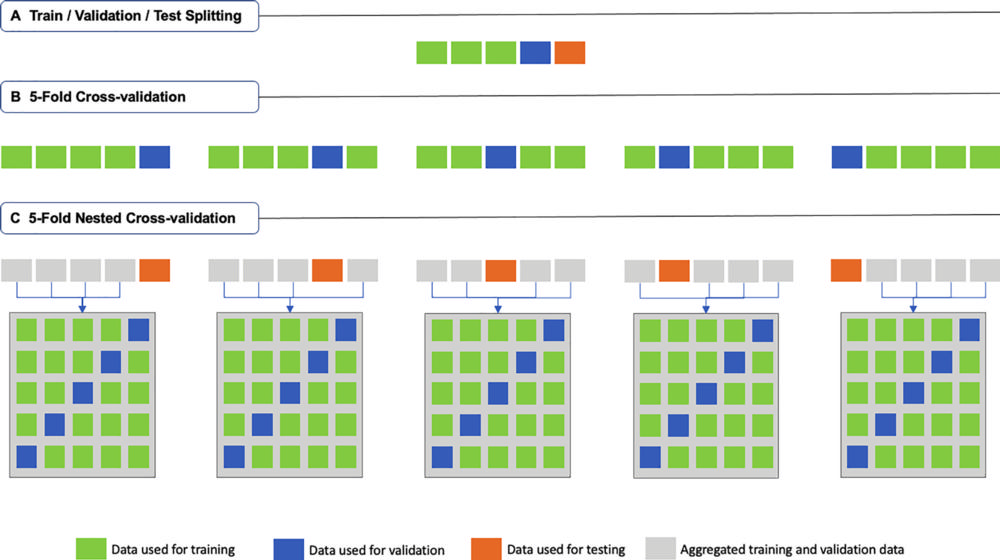
Figure 3. Schematic description of (A) traditional train-validation-test splitting, (B) fivefold cross-validation (k = 5; where k is the number of folds), and (C) fivefold nested cross-validation (k = m = 5; where k is the number of folds in the first-level cross-validation, and m is the number of folds in the second-level cross-validation).
High-res (TIF) version
(Right-click and Save As)
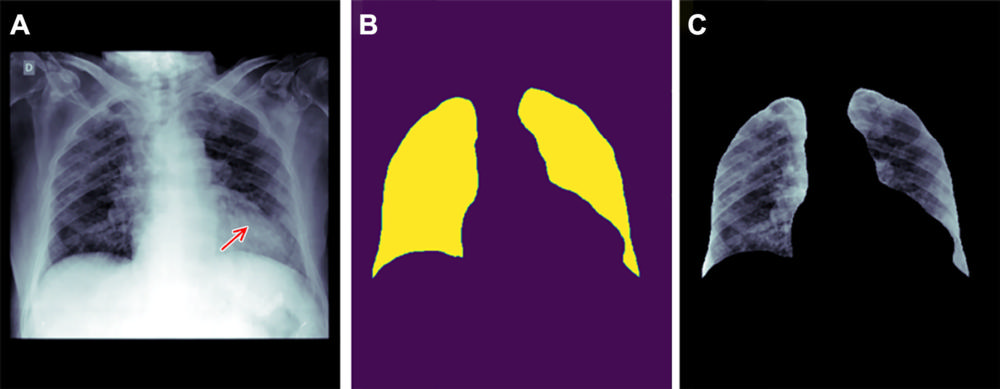
Figure 4. Example of how improper feature removal from imaging data may lead to bias. (A) Chest radiograph in a male patient with pneumonia. (B) Segmentation mask for the lung, generated using a deep learning model. (C) Chest radiograph is cropped based on the segmentation mask. If the cropped chest radiograph is fed to a subsequent classifier for detecting consolidations, the consolidation that is located behind the heart will be missed (arrow, A). This occurs because primary feature removal using the segmentation model was not valid and unnecessarily removed the portion of the lung located behind the heart.
High-res (TIF) version
(Right-click and Save As)